✨ AI에서의 유통과 데이터 플라이휠
Anthropic이 Windsurf의 모델 접근을 차단하면서 AI 업계에서 수직 계열화가 다시 화두에 올랐습니다.
제가 6개월 전에 수직 계열화에 대해 주장했던 핵심 논리는 여전히 유효합니다. 최고의 제품이 유통망을 확보하고, 이는 데이터를 낳으며, 그 데이터가 다시 제품을 개선한다는 것입니다.
검색과 데이터 플라이휠
Cursor의 CEO인 Michael Truell은 이러한 역학 관계를 인터넷 초창기의 검색 시장에 비유했습니다.
Ben Thompson: 앞으로 그것이 지속 가능한 진정한 경쟁 우위가 될 수 있을까요? 사용 데이터를 보유하고 있기 때문에 단순히 LLM을 호출하는 것을 넘어, 이제는 Cursor를 사용하는 사람들을 기반으로 자체 모델을 훈련하고 있으니까요. 처음에는 코드의 전체 컨텍스트를 파악하는 것부터 시작했는데, 이제는 훈련에 사용할 자체 데이터를 확보한 셈입니다.
Michael Truell: 네, 저는 그것이 큰 이점이라고 생각합니다. 높은 성장 잠재력, 여러 제품 중 선택할 수 있는 환경, 그리고 유통망이 데이터를 가져와 제품 개선에 도움을 주는 세 번째 역학까지, 이 세 가지 모두 90년대 말과 2000년대 초 검색 시장의 특징이었습니다. 그래서 여러 면에서 우리 시장의 경쟁 역학은 일반적인 기업용 소프트웨어 시장보다는 검색 시장과 더 유사하다고 생각합니다.
사용자 행동 데이터에 대한 강화 학습(RL)은 AI 시대의 네트워크 효과와 같습니다.
실제로 사용자 행동을 집계하거나 수집하는 제품을 보유하는 것은 매우 가치 있는 일입니다. 그것이 궁극적으로 가장 중요한 데이터셋이기 때문입니다. 여기서 흥미로운 점 한 가지는, 사용자 데이터를 보유한 AI 스타트업은 데이터를 인공적으로 생성하기 위해 막대한 컴퓨팅 예산 없이도 강화 학습(RL)을 통해 맞춤형 모델을 만들 수 있다는 것입니다.
Dylan Patel
Anthropic은 이러한 역학 관계가 결국 (Windsurf를 인수한) OpenAI에게 유리하게 작용할 것을 알고 있었습니다. 공동 창업자 Ben Mann의 말입니다.
전형적인 스타트업 창업자의 관점에서 볼 때, 저는 코딩이라는 애플리케이션을 전적으로 고객사에게만 맡길 수는 없다고 느꼈습니다. 저희 모델을 많이 사용해 온 Cursor나 GitHub 같은 파트너사들도 소중하지만, 코딩 사용자들과 직접적인 관계를 맺지 않으면 저희가 배우는 양과 속도가 훨씬 줄어들게 됩니다.
Anthropic은 Cursor와 같은 고객으로부터 수익을 얻어야 하지만, 궁극적으로는 Cursor가 데이터 우위를 바탕으로 시간이 지나면서 Anthropic을 완전히 범용화(commoditise)시킬 위험을 안고 있습니다. 현재로서는 둘이 공존할 수 있지만, 장기적으로 정면 대결은 피할 수 없습니다. Windsurf의 사례는 이 점을 훨씬 더 명확하게 보여줍니다.
AI 시장의 경쟁 역학이 전통적인 기업용 소프트웨어보다 검색 시장에 더 가깝다면, 이는 몇 가지 시사점을 가집니다.
유통 > 기술
AI 분야에서 제품을 만드는 창업자들은 두 가지 상충하는 아이디어를 동시에 고민해야 합니다.
한편으로 AI는 새로운 공급업체들이 제품을 처음부터 다시 만들어 시장 점유율을 차지할 수 있는 플랫폼 전환을 의미합니다.
다른 한편으로는, 유통망이 데이터를 낳고 그것이 더 나은 제품으로 이어진다면 기존 강자들이 승리해야 하지 않을까요?
그 균형점은 바로 최소 기능 품질(Minimum Viable Quality)입니다.
소비자 인터넷 대기업들과 비교했을 때 OpenAI와 ChatGPT의 빠른 성장이 이 점을 증명합니다.
2022년 10월에 출시된 ChatGPT 버전은 단순했습니다. 하지만 API로서의 GPT-3와 비교했을 때, 제품으로서의 ChatGPT가 가진 차별점 덕분에 현재의 AI 열풍이 시작될 수 있었습니다.
모두가 속도를 이야기하는 데는 이유가 있습니다.
빠르게 제품을 출시하는 회사들은, '뚱뚱한 스타트업(fat startup)' 모델보다 최소 기능 품질 기준을 충족하는 기능들을 자주 출시하는 것이 시장 점유율과 데이터 플라이휠을 확보하는 데 더 유리하다는 점을 인지하고 있습니다.
Patrick O’Shaughnessy는 2020년 Rahul Vohra를 인터뷰하며 Superhuman의 사례를 통해 이러한 트레이드오프에 대해 질문했습니다.
PS: 기술 창업계에서 제가 가장 좋아하는 논쟁 중 하나는, 고객 피드백을 통해 반복하고 많이 실패하며 배우는 '린(lean) 모델'과, Keith Rabois의 '영화 제작 모델' 사이의 논쟁입니다. 후자는 마치 배우와 각본 등 모든 것이 준비된 영화처럼, 오랜 기간 큰 노력을 들여 대단한 제품을 시장에 내놓는, 당신이 해온 방식과 더 비슷해 보입니다. 군중 속에서 반복적으로 개선된 제품이 아니라요.
RV:
참고로, 2015년 여름 저희는 다른 소프트웨어 회사들처럼 코드를 작성하며 시작했습니다. 2016년 여름에도 저희는 여전히 코딩 중이었습니다. 2017년 여름에도 마찬가지였죠. 저는 출시해야 한다는 엄청나고 강렬한 압박감을 느꼈습니다. 2년이나 지났는데 아직 출시를 못 했으니까요. 하지만 마음속 깊은 곳에서는, 그 압박이 아무리 강해도 섣불리 출시하면 결과가 매우 나쁠 것이라는 걸 알고 있었습니다. 우리 제품이 시장 적합성(product market fit)을 갖췄다고 믿지 않았기 때문입니다.
그래서 2017년 4월, 저는 그 성배를 찾기 시작했습니다. 제품 시장 적합성을 정의하는 방법, 그것을 측정하는 지표, 그리고 체계적으로 높이는 방법론을요. 이것이 바로 제가 '제품 시장 적합성 엔진'을 만들게 된 계기이며, 많은 분이 저를 아는 이유이기도 합니다. 사실 이것은 린 스타트업 모델과 Keith Rabois의 팻 스타트업 모델, 즉 영화 제작 모델을 혼합한 것입니다.
저는 사실 두 가지 모두를 강력히 믿으며, 저희는 그 중간 어디쯤에 있다고 말하고 싶습니다. 저는 초기에 막대한 자본을 유치하라고 말하고 싶습니다. 가능한 한 장기적인 관점에서 결정하라고 말하고 싶습니다. 최소 기능 제품(MVP)이 아니라, 극도로 만족스러운 제품(maximally delightful product)을 내놓으라고 말하고 싶습니다. 하지만 동시에, 사용자의 말에 매우 주의 깊게 귀를 기울이라고도 말하고 싶습니다.
오늘날 AI 환경의 속도와 우리가 목격하고 있는 엔지니어링 생산성을 고려할 때, Superhuman의 접근 방식이 통할까요? 아마 아닐 겁니다.
전통적인 기업용 소프트웨어의 방어 기제는 연동(integration)과 전환 비용(switching cost)이었습니다. 하지만 AI 앱이 검색 엔진과 더 유사하다면, 최종 사용자가 몇 시간씩 작업하는 클라이언트가 되는 것이 AI 스택에서 가장 가치 있는 위치입니다.
LibreChat과 클라이언트의 미래
LibreChat은 ChatGPT의 오픈소스 대안으로, 현재 GitHub에서 일일 트렌딩 저장소 1위를 차지하고 있습니다.
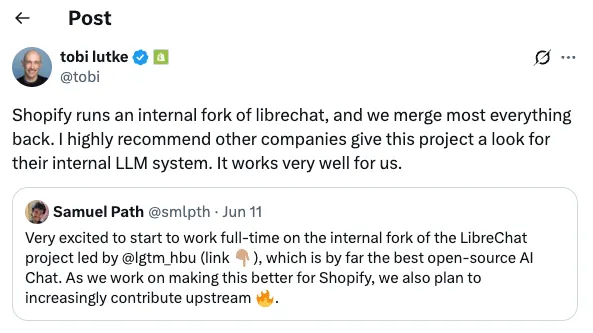
개발자들은 멀티 모델 라우팅, 에이전트, 코드 인터프리터, 툴 호출 기능을 사용할 수 있으며, Shopify와 같은 회사들이 LibreChat을 포크(fork)하여 개발에 적극적으로 기여하고 개선 사항을 다시 업스트림에 병합하면서 인증(auth), SSO 등 엔터프라이즈급 기능도 점점 늘어나고 있습니다.
앞서 논의했던 플라이휠은 누가 최종 사용자를 소유하고, 나아가 그들의 행동 데이터를 확보하느냐에 달려 있습니다.
LibreChat은 기업 내에서 ChatGPT나 Claude와 같은 클라이언트를 대체하고, 기업이 자체적인 데이터 플라이휠을 구축하도록 도울 수 있다는 점에서 위협적입니다.
Dylan Patel: 기업들이 적절한 강화 학습(RL) 환경을 구축할 수만 있다면, 기업을 위한 맞춤형 모델의 시대가 의미를 가질 수 있습니다. 지금까지 기업을 위한 모델 파인튜닝은 파운데이션 모델의 끊임없는 발전에 밀려 대체로 실패했습니다.
프로덕션 환경에서 실행하고 전체 로깅을 활성화하기만 하면, Claude, Cursor, ChatGPT 같은 클라이언트들이 좇는 독점적인 데이터 플라이휠과 동일한 기반을 갖추게 됩니다. 단, 여러분의 기업이 중요하게 생각하는 특정 도메인을 목표로 한다는 점이 다릅니다.
이는 사용자들이 앱 간 전환에 시간을 덜 쓰고 단일 창(one pane of glass)에서 더 많은 작업을 수행하는 '포스트-MCP(Multi-Copilot Platform)' 시대에 특히 더 그렇습니다.
이것이 시사하는 바는, 기업 내에 더 많은 소형 언어 모델(SLM)이 도입되고, ChatGPT 사용은 줄어들며, API 호출이 여러 다른 모델에 걸쳐 더 고르게 분산될 것이라는 점입니다.
현재로서는 LibreChat이 단순한 채팅 인터페이스를 가진 클라이언트에게만 위협이 됩니다. 하지만 시간이 지나면서 워크플로우에 내장된 다른 클라이언트의 영역까지 잠식하기 시작할 수 있습니다. 더 많은 기업이 자체적인 내부 포크를 개발함에 따라, 이러한 변화는 머지않아 일어날 가능성이 높습니다.
Source
Comments ()